Sub-Word Tokenization: Breaking Words Like a Pro
Remember when I promised we’d dive into Transformers in the next post? The auto-complete-on-steroids that powers LLMs? Yeah… well, I lied. 😬 But trust me, this detour is worth it. Before we get all transform-y, we need to cover tokenization—the real MVP when it comes to how LLMs understand language. Think of this as the scenic route before the rollercoaster.
So buckle up, because today we’re talking about sub-word tokenization—the art of slicing and dicing words like a linguistic ninja!
What is Tokenization?
Okay, okay. I know you’re thinking: “What the heck is tokenization? Did I sign up for a cryptography lesson?!” Calm down! Tokenization isn’t that complicated, even if it sounds like I just made it up.
In simple terms, tokenization is the process of breaking down text into smaller pieces. You start with a word or sentence and split it into tiny chunks—tokens. You’ve probably done this without knowing. Ever tried pronouncing a long word and just gave up halfway? Yeah, that’s tokenization. (Okay, not exactly, but close enough.)
More formally: LLMs use previous tokens (a fancy way of saying “words or pieces of words”) as context to predict the next word. But what if we can reduce the number of words without losing the meaning? Enter tokenization! 🙌
Sub-word Units: When Words Are Just Too Much
Not only can we reduce the number of words, but we can also shrink individual words into sub-word units. Why? Because sometimes breaking a word into pieces is like getting to the juicy center of a Tootsie Pop.
Sub-word units are magical little chunks smaller than a word but bigger than a character. They’re perfect for dealing with languages that like to complicate things (looking at you, German) or for when your model can’t find a word in its vocabulary. Think of them as backup units for rare words, superheroes in their own right.
For example: The word unhappiness becomes:
- un
- happi
- ness
Boom. Now your model knows what’s going on without needing the entire word. Genius, right?
Why Should You Care About Sub-word Units?
Great question! Here’s why sub-word units are essential:
- Dealing with rare words: Sub-word units handle out-of-vocabulary (OOV) words by breaking them down into smaller, understandable pieces. It’s like finding Lego blocks you forgot under the couch.
- Reducing vocabulary size: Instead of feeding the model a dictionary’s worth of words, you simplify things.
- Handling morphology: Sub-word units help capture parts of words like prefixes and suffixes, making it easier for models to understand rich languages. Unbelievable! (See what I did there?)
LLM models like SentencePiece and TikToken are based on these sub-word tokenization techniques.
Meet the Sub-word Titans: BPE, WordPiece, and Unigram
Ready to meet the big three? These are the all-stars of sub-word tokenization techniques:
- Byte-Pair Encoding (BPE): The one that keeps merging till it’s done.
- WordPiece: The careful optimizer, focused on word likelihood.
- Unigram Language Model: The probability pro, cutting down words like a math whiz.
Byte-Pair Encoding (BPE): The Merger King
Byte-Pair Encoding (BPE) is like a matchmaker. It looks for the most common pairs of characters in a text and merges them until you get a nice, compact set of sub-word tokens. It’s frequency-driven and loves to merge.
Here’s how BPE works in four easy steps:
- Start with individual characters: Treat each character as a token.
- Find the most frequent pair: The most popular couple in the text.
- Merge the pair: They become one!
- Repeat: Until no more frequent pairs remain or you hit your token limit.
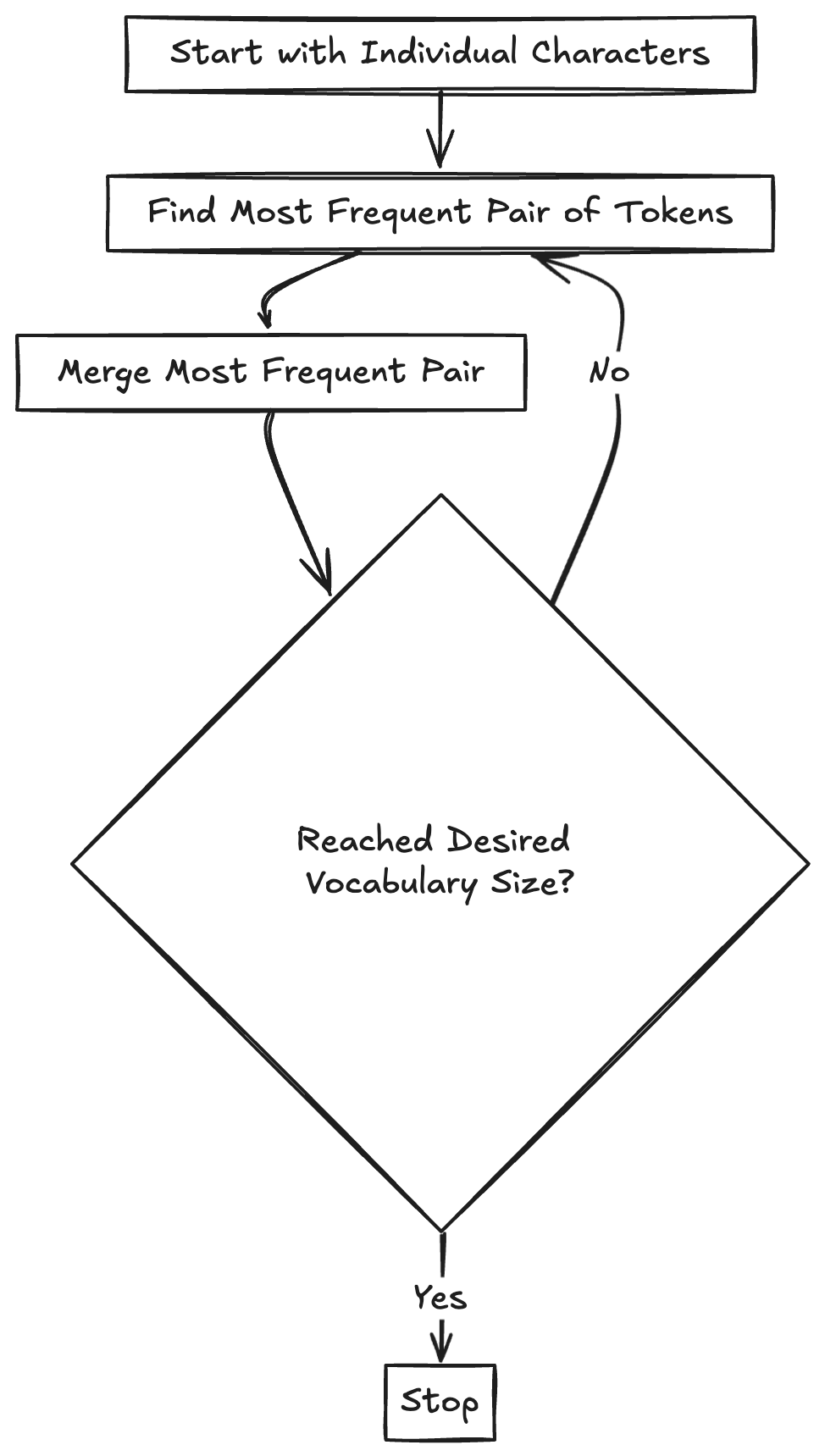
BPE in Action: Let’s tokenize these words: low, lower, newest, widest.
low -> ['l', 'o', 'w']
lower -> ['l', 'o', 'w', 'e', 'r']
newest -> ['n', 'e', 'w', 'e', 's', 't']
widest -> ['w', 'i', 'd', 'e', 's', 't']
Step 1: Initialize with individual characters. The initial tokenization breaks each word into individual characters:
low -> ['l', 'o', 'w']
lower -> ['l', 'o', 'w', 'e', 'r']
newest -> ['n', 'e', 'w', 'e', 's', 't']
widest -> ['w', 'i', 'd', 'e', 's', 't']
Step 2: Find the most frequent pair. Let’s count the pairs of consecutive tokens:
- (’l’, ‘o’): 2 occurrences
- (‘o’, ‘w’): 2 occurrences
- (‘w’, ’e’): 2 occurrences
- (’e’, ’s’): 2 occurrences
- (’s’, ’t’): 2 occurrences
- (’n’, ’e’): 1 occurrence
- (‘i’, ’d’): 1 occurrence
- (’d’, ’e’): 1 occurrence
The most frequent pair is (’l’, ‘o’), so we merge ‘l’ and ‘o’ into the token ‘lo’.
Step 3: Merge the most frequent pair. After merging, the tokens become:
low -> ['lo', 'w']
lower -> ['lo', 'w', 'e', 'r']
newest -> ['n', 'e', 'w', 'e', 's', 't']
widest -> ['w', 'i', 'd', 'e', 's', 't']
Step 4: Repeat the process. Now we find the most frequent pair again. The new counts are:
- (’lo’, ‘w’): 2 occurrences
- (‘w’, ’e’): 2 occurrences
- (’e’, ’s’): 2 occurrences
- (’s’, ’t’): 2 occurrences
The most frequent pair is (‘lo’, ‘w’), so we merge ‘lo’ and ‘w’ into ‘low’.
The tokens now look like:
low -> ['low']
lower -> ['low', 'e', 'r']
newest -> ['n', 'e', 'w', 'e', 's', 't']
widest -> ['w', 'i', 'd', 'e', 's', 't']
Step 5: Continue merging. We repeat this process, merging the next most frequent pairs (w, e, and others) until we reach a predefined vocabulary size or the process stops yielding new merges.
Step by step, BPE merges pairs and shrinks everything down to manageable tokens. Efficiency at its best!
WordPiece: The Smart Tokenizer
WordPiece is the overachiever in the room. It doesn’t just merge tokens blindly like BPE—it calculates the probability of token combinations and picks the ones that maximize the likelihood of making sense. Smart, right?
BPE is a frequency-driven tokenization technique, while WordPiece focuses on improving the likelihood of the model by optimizing token selections. WordPiece is often more flexible and conservative in merging subwords, which tends to perform better in tasks like language modeling and classification, where prediction accuracy is critical.
How it works:
- Start with a whole word.
- Split it into subwords, starting from the longest match in the vocabulary.
- Keep going until you’ve tokenized the whole word.
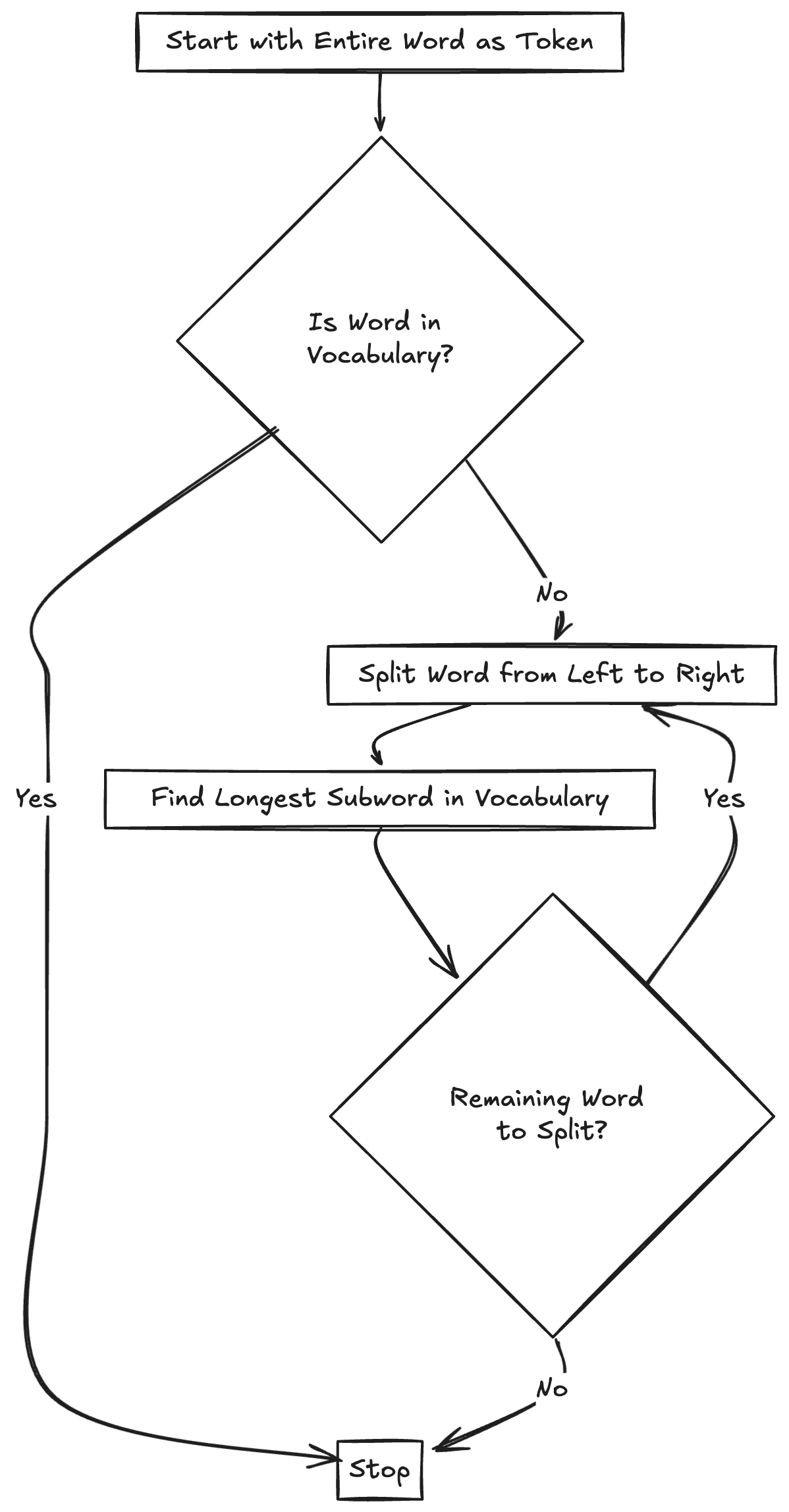
Example: Let’s assume we have the word unhappiness and a pre-defined vocabulary with the following tokens:
["un", "happy", "##ness", "##p", "##i", "##ness"]
Note: This vocabulary is learned during the pre-training phase of models like BERT or ALBERT.
That double hash (##) means the sub-word is part of a bigger word. It’s like the model whispering: “Psst, I know this is a fragment.”
Step 1: Start with the entire word. We start by checking if the word unhappiness exists as a whole in the vocabulary. Since unhappiness is not in the vocabulary, we will break it into subwords.
Step 2: Split the word from left to right. WordPiece breaks the word from left to right, trying to find the longest match in the vocabulary.
- The first match from the left is un, which is in the vocabulary.
- We split the word into un and happiness. Now the remaining part of the word is happiness.
Step 3: Continue breaking down the remaining part. Since happiness is not in the vocabulary, WordPiece will try to split it further:
- It finds that happy is in the vocabulary.
- So, happiness is split into happy and ness. Next, we check the remaining part of the word, which is ness.
Step 4: Final match for the remaining part. The subword ness is not in the vocabulary as a standalone token, but ##ness (as a suffix) is in the vocabulary. So, WordPiece uses ##ness.
Result: The word unhappiness is tokenized as:
["un", "happy", "##ness"]
This is the final tokenization because the word has been completely broken into subwords, all of which exist in the vocabulary.
Visualization of the Process:
- unhappiness
- Unmatched: Not in vocabulary
- Split into un + happiness
- happiness
- Unmatched: Not in vocabulary
- Split into happy + ness
- ness
- Unmatched: Not in vocabulary
- Found matching subword: ##ness
Final tokens:
["un", "happy", "##ness"]
Another Example: Let’s consider a different word, unpredictably, with the following vocabulary:
["un", "predict", "##able", "##ly"]
Step 1: Start with the entire word. We start with the word unpredictably. It is not in the vocabulary, so we need to break it down.
Step 2: Split the word from left to right. From left to right, we first find un in the vocabulary:
- The word is split into un and predictably.
Step 3: Continue breaking the remaining part. Next, the remaining word is predictably.
- We find that predict is in the vocabulary, so we split predictably into predict and ably. Now we need to tokenize the remaining part, ably.
Step 4: Continue splitting the rest. The subword ably is not in the vocabulary, but WordPiece finds the longest match, which is ##able.
- We split ably into ##able and ly. Finally, the subword ly is matched with ##ly in the vocabulary.
Result: The word unpredictably is tokenized as:
["un", "predict", "##able", "##ly"]
Unigram Language Model: The Pruner
The Unigram Language Model is the “Marie Kondo” of tokenization—it starts with a massive vocabulary and then prunes it down. Instead of building from the bottom up like BPE, it goes the opposite way, cutting out the unnecessary and keeping only what sparks joy (or likelihood).
The Unigram Language Model is a subword tokenization approach used in natural language processing (NLP). Unlike Byte-Pair Encoding (BPE) or WordPiece, which iteratively merge or split tokens based on frequency, the Unigram model starts with a large set of subword candidates and prunes them down based on probabilities.
The key idea behind the Unigram model is that every subword unit is treated as independent, and the model selects the optimal set of subwords based on likelihood. This is especially useful in models like SentencePiece, which is widely used in Google’s T5 and ALBERT models.
Steps:
- Start with all possible subword candidates.
- Calculate likelihoods of words based on those candidates.
- Prune the low-likelihood subwords.
- Tokenize the remaining words.
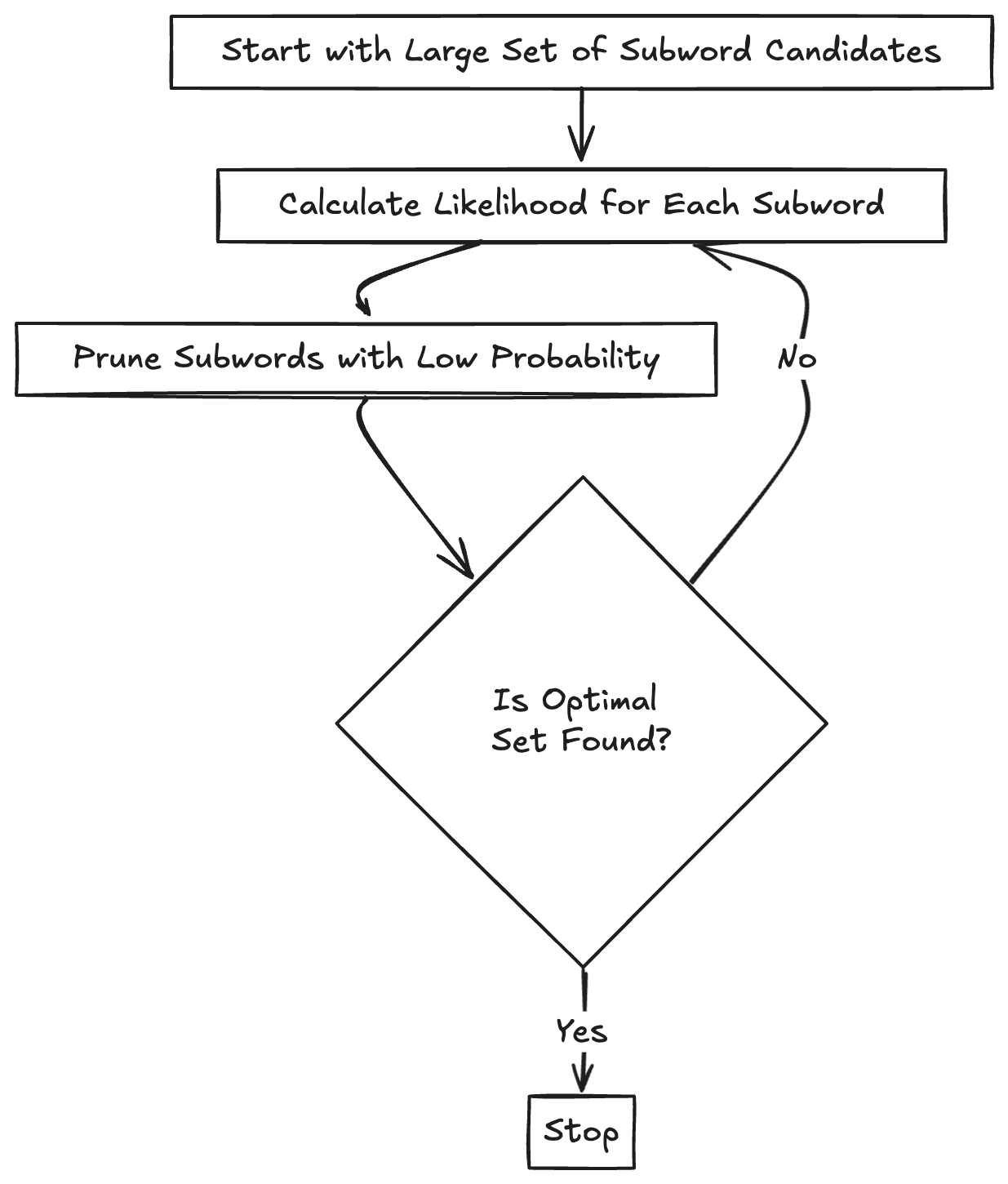
Example of Unigram Language Model: Let’s walk through a simplified example of how a Unigram model works.
Corpus: Suppose we have a very small corpus:
[‘low’, ‘lower’, ‘newest’, ‘widest’]
Step 1: Initialize the Vocabulary The model starts with a large set of subword candidates. This could include the full words, characters, and fragments:
Vocabulary: ["l", "lo", "low", "o", "e", "r", "er", "new", "newest", "wide", "wid", "est", "t"]
Step 2: Compute the Likelihood For each word in the corpus, we compute the likelihood of the word being generated by different combinations of subwords. For example:
- “low” can be represented by:
- “low” (as a whole word)
- or by the subwords: “lo” + “w”
- “newest” can be represented by:
- “new” + “est”
- or by “newest” as a whole word. The likelihood for each representation is calculated using probabilities associated with the subwords.
Step 3: Prune the Vocabulary The Unigram model iteratively removes subwords that contribute the least to the overall likelihood of the corpus. Let’s say the subword “lo” is rarely used, and thus its probability is very low. The model will prune it. Similarly, subwords like “t” and “wide” may also be removed if they are rarely useful for representing the words in the corpus.
After pruning, the vocabulary might look like this:
Pruned Vocabulary:
["low", "new", "est", "wid", "er"]
Step 4: Final Tokenization For a new word, the Unigram model selects the sequence of subwords from the final pruned vocabulary that maximizes the likelihood of the word.
For instance:
- Tokenizing “lower”:
- The Unigram model can represent it as [“low”, “er”] because “low” and “er” are in the pruned vocabulary.
- Tokenizing “newest”:
- The model splits “newest” into [“new”, “est”].
Example of Tokenization: Let’s tokenize the word “lower” with the pruned vocabulary:
- Word: “lower”
- The model looks at possible subword sequences:
- “low” + “er” (both in the pruned vocabulary)
- The model looks at possible subword sequences:
- Result:
- The tokenized output is [“low”, “er”].
Similarly, for “newest”:
- Word: “newest”
- The possible subword sequence is “new” + “est”, both of which are in the vocabulary.
- Result:
- The tokenized output is [“new”, “est”].
If we were to throw these tokenization techniques into a friendly comparison arena, here’s how they’d stack up (without throwing any punches, of course!):
| Feature | Byte-Pair Encoding (BPE) | WordPiece | Unigram Language Model |
|---|---|---|---|
| Algorithm Type | Frequency-based iterative merging of character pairs | Likelihood-based, focusing on maximizing token sequence probability | Probabilistic model, starts with a large set and prunes tokens based on likelihood |
| Initial Tokenization | Starts with individual characters | Starts with the whole word, splits left-to-right | Starts with a large predefined vocabulary of sub-words |
| Merging/Pruning Strategy | Most frequent consecutive characters are merged | Splits based on maximizing likelihood of tokens | Prunes tokens based on probabilities to find the most likely segmentation |
| Handling of Rare/OOV Words | Breaks down rare words into sub-words based on character frequency | Breaks rare words into smaller known pieces, uses prefixes like ## | Similar to BPE but may be more flexible in handling rare tokens due to pruning |
| Vocabulary Size | Controlled by the number of merge operations | Controlled by vocabulary likelihood | Controlled by predefined vocabulary, prunes irrelevant tokens |
Example Tokenization of unhappiness | ['un', 'happiness'] (or similar split based on frequency) | ['un', '##happiness'] or ['un', '##hap', '##piness'] | ['un', 'happy', '##ness'] |
| Efficiency | Efficient in reducing vocabulary size and handling OOV words | More computationally efficient than BPE, often better for language modeling | Balances flexibility and efficiency with a probabilistic approach |
| Common Usage | Used in models like GPT (early versions) | Used in models like BERT | Used in models like SentencePiece |
| Key Advantage | Simple to implement and efficient | Produces tokens that maximize model accuracy | More flexible in token segmentation with a probabilistic approach |
| Key Drawback | May not always select the most optimal tokens for all tasks | More complex to implement than BPE | Requires larger initial vocabulary and more complex calculations |
Well, if you want your LLM to handle rare or unknown words like a champ, tokenize your text efficiently, or even work with languages that have rich structures, sub-word tokenization is the way to go. Plus, when we finally dive into Transformers, you’ll see how all this fits together to create that “auto-complete on steroids” magic.
Stay tuned for the next post, where we’ll (hopefully) actually get to Transformers. Maybe. Probably. No promises.
Until then, happy tokenizing! Or at least, happy reading about tokenizing.
If you’re a Gopher, be sure to check out the Golang implementation of these tokenization techniques.
Share This Post
If you found this post helpful or entertaining, please share it with your friends!
Share on Twitter
Share on Facebook
Share on LinkedIn
Share on Reddit