Retrieval Pipelines, Re-Ranking, and Grounding: Building Production RAG
Note: This post was AI-generated from rough notes using the blog generation workflow.
Most RAG tutorials stop at “embed your docs, do a vector search, pass results to an LLM.” That works fine for demos. In production, it falls apart — wrong chunks get retrieved, the LLM confidently makes things up, and users stop trusting the system. This post covers the full pipeline: hybrid retrieval, re-ranking, and grounding, with real code and examples throughout.
Dense Retrieval: Meaning Over Words
The baseline approach is dense retrieval. You embed the query, find chunks with the closest vectors in your vector store, and return the top K results. The key insight is that it works on meaning, not exact words.
This is genuinely useful. A query like “handle null reference error in billing service” will match a chunk containing “NullPointerException in payment module” because their embeddings land close together in vector space — the concepts align even though the words don’t overlap.
Dense retrieval also works reasonably well across languages and handles paraphrasing naturally. It’s a solid default.
The weakness: dense retrieval can miss exact matches. If someone queries for a specific error code like ERR_PAYMENT_4032, a version number like v2.3.1, or a product SKU, the embedding model might not preserve that specificity. The vector for “ERR_PAYMENT_4032” and “ERR_PAYMENT_4033” could end up uncomfortably close.
Sparse Retrieval: When Exact Words Matter
BM25 is old-school information retrieval — keyword-based scoring that most engineers learned about and then forgot once neural search became fashionable. It deserves a second look.
BM25 scores documents based on exact word frequency, inverse document frequency (rare words score higher), and document length normalization. There’s no embedding, no semantic understanding — just precise term matching.
Consider a query: "NullPointerException payment module". BM25 scoring might look like this:
"NullPointerException occurs in the payment module when processing refunds"→ score 0.91"how to handle null errors in billing service"→ score 0.21
The exact terminology wins. This is exactly where dense retrieval struggles. For error codes, product names, IDs, and version numbers, BM25 consistently outperforms vector search.
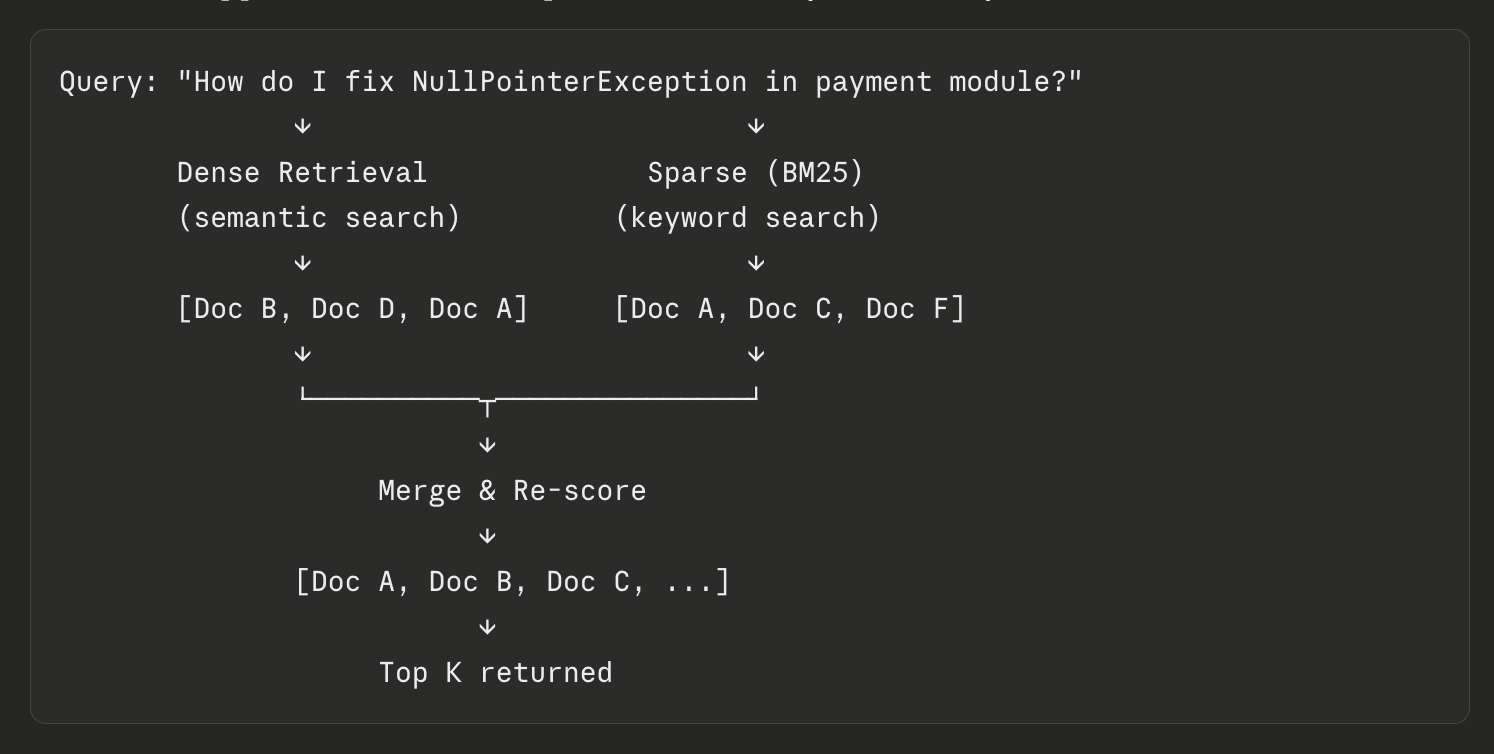
Hybrid Retrieval: Run Both, Merge with RRF
The practical answer is to run both retrieval methods and combine the results. Neither approach dominates across all query types, so use both.
The standard merging strategy is Reciprocal Rank Fusion (RRF). Instead of trying to normalize raw scores across two incompatible systems, RRF scores each result based purely on its rank position in each list. A document ranked 1st gets a higher contribution than one ranked 10th. Documents that rank well in both lists bubble to the top.
The formula is simple: for each document, sum 1 / (k + rank) across all lists, where k is a constant (usually 60) that dampens the influence of top ranks.
A concrete example:
- Doc A: ranked 3rd in dense, ranked 1st in sparse → high combined RRF score
- Doc B: ranked 1st in dense, ranked 8th in sparse → medium combined RRF score
Doc A wins even though it wasn’t the top dense result, because it performed consistently across both retrieval methods.
Here’s a simplified implementation of RRF:
def reciprocal_rank_fusion(rankings: list[list[str]], k: int = 60) -> dict[str, float]:
"""
rankings: list of lists, each containing doc IDs in ranked order
returns: dict of doc_id -> combined RRF score
"""
scores = {}
for ranked_list in rankings:
for rank, doc_id in enumerate(ranked_list, start=1):
if doc_id not in scores:
scores[doc_id] = 0.0
scores[doc_id] += 1.0 / (k + rank)
return dict(sorted(scores.items(), key=lambda x: x[1], reverse=True))
Check out the full retrieval implementation in the demo code.
Re-Ranking: A Second, Slower, More Accurate Pass
Retrieval is fast and approximate. The most relevant chunk might come back at position 6, not position 1. That’s acceptable — retrieval is a recall problem. Re-ranking is where you fix precision.
The pipeline looks like this:
millions of chunks
→ fast hybrid retrieval → top 20 candidates
→ cross-encoder re-ranker → top 3–5 results
→ sent to LLM
The key component is the cross-encoder. Unlike bi-encoders (which embed query and document separately and compare vectors), a cross-encoder takes the query and document together as a single input and outputs a relevance score between 0 and 1. Because it sees both texts simultaneously, it can model fine-grained interactions between them — it’s slower, but significantly more accurate.
Example with the query "NullPointerException in payment module?":
| Chunk | Retrieval Rank | Re-ranker Score |
|---|---|---|
| “NullPointerException in payment module when…” | 3rd | 0.94 |
| “General null handling patterns in Java” | 1st | 0.41 |
| “Payment module architecture overview” | 2nd | 0.38 |
| “Error handling best practices” | 4th | 0.22 |
Re-ranking corrected the order. The chunk that actually answers the question was buried at position 3 after retrieval — after re-ranking, it’s first.
Popular tools for re-ranking:
- Cohere Rerank — hosted API, easy to drop in
- FlashRank — lightweight, runs locally, good for cost-sensitive setups
- BGE Reranker — open-source, strong performance on technical content
from flashrank import Ranker, RerankRequest
ranker = Ranker(model_name="ms-marco-MiniLM-L-12-v2")
passages = [
{"id": 1, "text": "General null handling patterns in Java"},
{"id": 2, "text": "Payment module architecture overview"},
{"id": 3, "text": "NullPointerException in payment module when processing refunds"},
{"id": 4, "text": "Error handling best practices"},
]
request = RerankRequest(query="NullPointerException in payment module?", passages=passages)
results = ranker.rerank(request)
for r in results:
print(f"Score: {r['score']:.2f} | {r['text'][:60]}")
Grounding: Keeping the LLM Honest
Here’s the uncomfortable truth about LLMs: they’re trained to be helpful and fluent. When they don’t know something, they don’t say “I don’t know” — they pattern-match to what sounds plausible and say it confidently. RAG is fundamentally a grounding technique. The retrieved chunks act as guardrails that anchor the LLM’s answer to real source material.
This doesn’t happen automatically. You have to engineer it explicitly.
The Grounding Prompt Pattern
GROUNDED_PROMPT = """
Answer ONLY using the information provided in the context below.
If the answer is not present in the context, say: "I don't have enough information to answer this."
Context:
{context}
Question: {question}
"""
Two things matter here: telling the model to use only the provided context, and explicitly giving it permission to say it doesn’t know. That second part is important — by default, LLMs resist admitting ignorance because they’re trained to be helpful. You need to override that default.
Citation Forcing
For higher-stakes applications, go further: ask the model to quote the exact chunk it’s answering from. If it can’t point to a source, it can’t answer.
CITATION_PROMPT = """
Answer the question below using ONLY the provided context.
For each claim in your answer, quote the exact sentence from the context that supports it.
If you cannot find a supporting quote, do not make the claim.
Context:
{context}
Question: {question}
Format your response as:
Answer: [your answer]
Supporting quote: "[exact quote from context]"
"""
This forces the model to stay honest. It’s harder to hallucinate when you have to show your work.
Faithfulness Checking
For production systems where wrong answers have real consequences, run a second LLM call after the answer is generated:
FAITHFULNESS_CHECK_PROMPT = """
Given the following context and answer, does the answer contain any claims NOT supported by the context?
Respond with a score from 0.0 to 1.0 where 1.0 means fully grounded and 0.0 means completely unsupported.
Also list any unsupported claims.
Context: {context}
Answer: {answer}
"""
Tools like RAGAS and TruLens automate this with structured faithfulness scores you can log and alert on. Worth integrating into your eval pipeline early.
See the full grounding examples in 07_hallucinations_grounding.py.
The Full Pipeline
Put it all together and the production RAG pipeline looks like this:
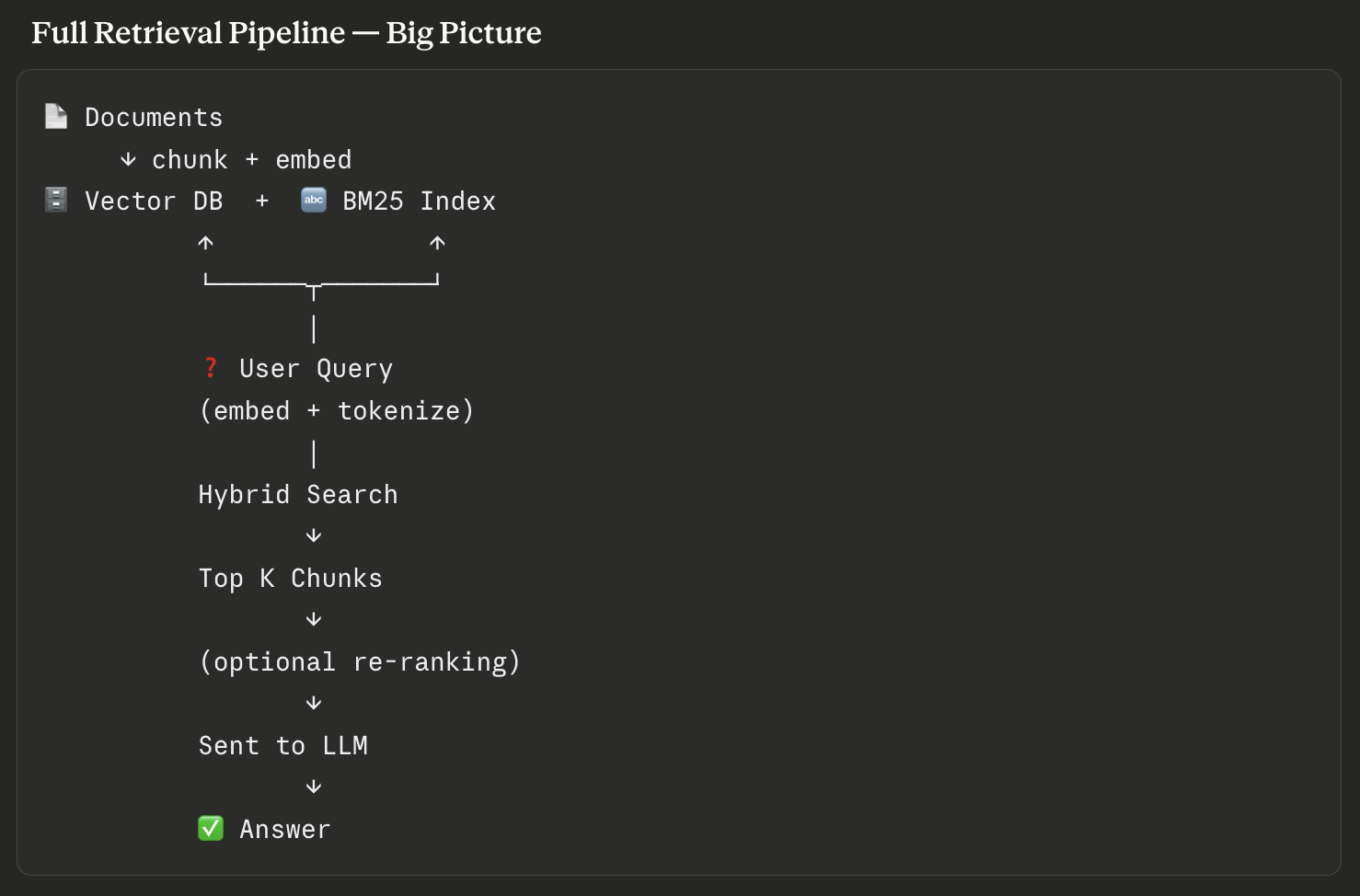
- Ingest: embed documents, chunk with metadata (source, section, timestamp)
- Store: vector DB for dense retrieval + inverted index for BM25
- Retrieve: run both, merge with RRF, get top 20 candidates
- Re-rank: cross-encoder scores candidates, keep top 3–5
- Generate: grounded prompt with explicit instructions and permission to say “I don’t know”
- Check: faithfulness score on the output for high-stakes use cases
Wrapping Up
The gap between a RAG demo and a RAG system that people actually trust comes down to these three things: getting the right chunks (hybrid retrieval + re-ranking), keeping the LLM anchored to those chunks (grounding), and verifying it stayed anchored (faithfulness checks).
None of this is magic. It’s engineering. Each piece is independently understandable and testable, which means you can add them incrementally and measure the improvement at each step. Start with hybrid retrieval if your current setup misses exact terms. Add re-ranking if retrieval precision is low. Add grounding prompts if the LLM is going off-script. Add faithfulness checks if wrong answers have real consequences.
Build it in layers, measure each one, and you’ll end up with a system worth trusting.