Inside the Machine: Encoders, Decoders, and Masking
Note: This post was AI-generated from rough notes using the blog generation workflow.
The original Transformer paper — “Attention Is All You Need” — introduced an architecture split cleanly into two halves: an encoder that reads and understands the input, and a decoder that generates the output one token at a time. If you’ve been working with LLMs and wondering what’s actually happening under the hood, this is the post for you. Let’s walk through each piece methodically.
The Encoder Stack
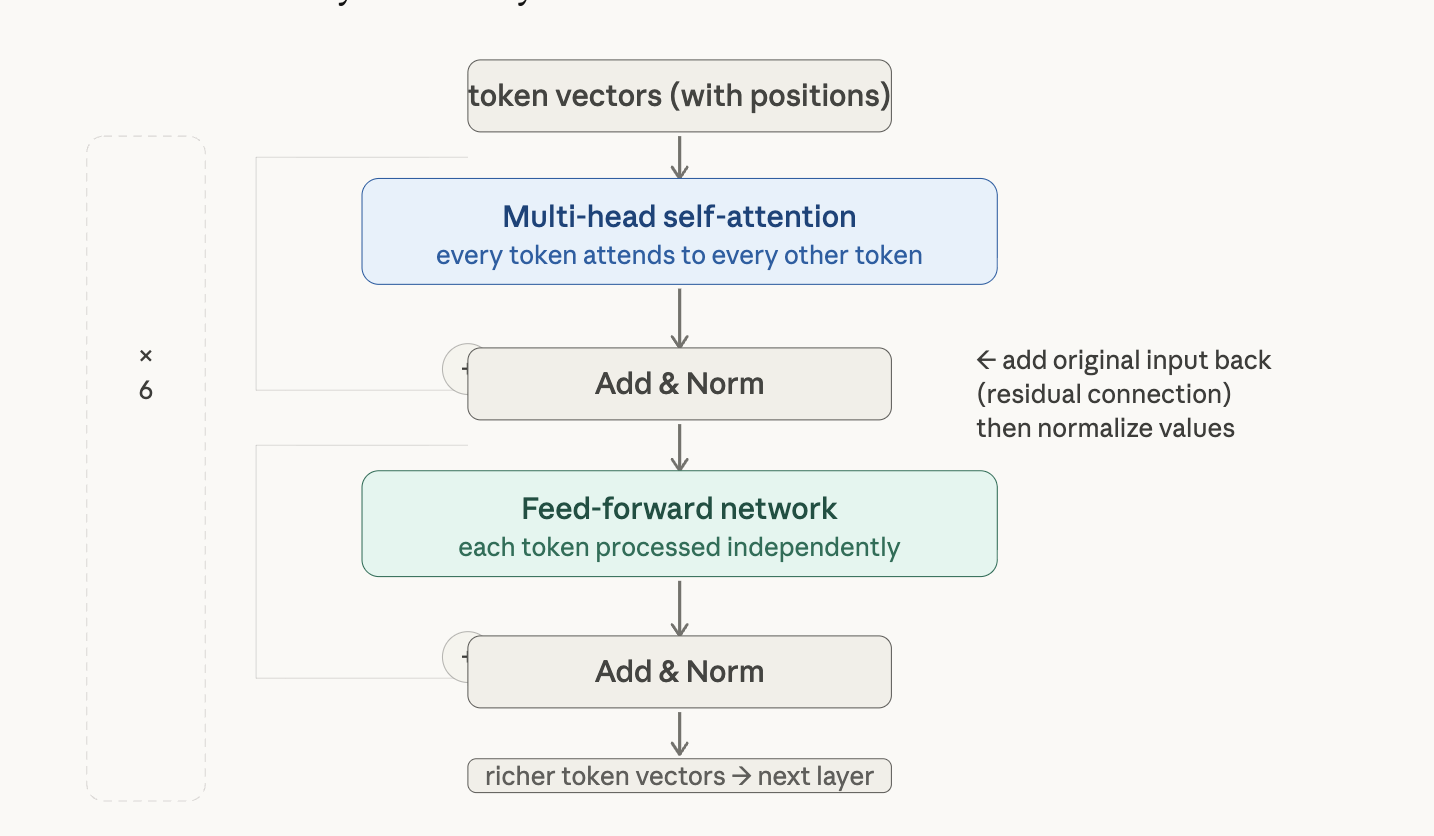
The encoder is a stack of 6 identical layers. That number isn’t magic — it’s a hyperparameter the original authors chose. You could use 4, or 12, or 24 (GPT-3 uses 96). The point is that each layer is a self-contained processing unit, and they’re stacked to build progressively richer representations.
Each encoder layer has two sub-layers:
- Multi-head self-attention — lets every token look at every other token in the input
- Position-wise Feed-Forward Network (FFN) — a small MLP applied independently at each position
The FFN is straightforward: two linear transformations with a ReLU in between.
import torch
import torch.nn as nn
class PositionwiseFFN(nn.Module):
def __init__(self, d_model=512, d_ff=2048):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.linear2(self.relu(self.linear1(x)))
Notice d_ff=2048 — the inner dimension is four times the model dimension d_model=512. Same FFN weights are applied at every position independently. Position 0 and position 15 go through the exact same transformation; they just carry different content by that point.
Residual Connections and Layer Norm
Every sub-layer is wrapped in a residual connection:
output = LayerNorm(x + Sublayer(x))
In code:
class SubLayerWrapper(nn.Module):
def __init__(self, d_model, sublayer):
super().__init__()
self.norm = nn.LayerNorm(d_model)
self.sublayer = sublayer
def forward(self, x):
return self.norm(x + self.sublayer(x))
The x + part is the shortcut. During backpropagation, gradients can flow directly through the addition operation without passing through the sub-layer — which is why deep networks train without vanishing gradients. Six layers of this is totally stable. Without it, you’d be fighting gradient decay the whole way down.
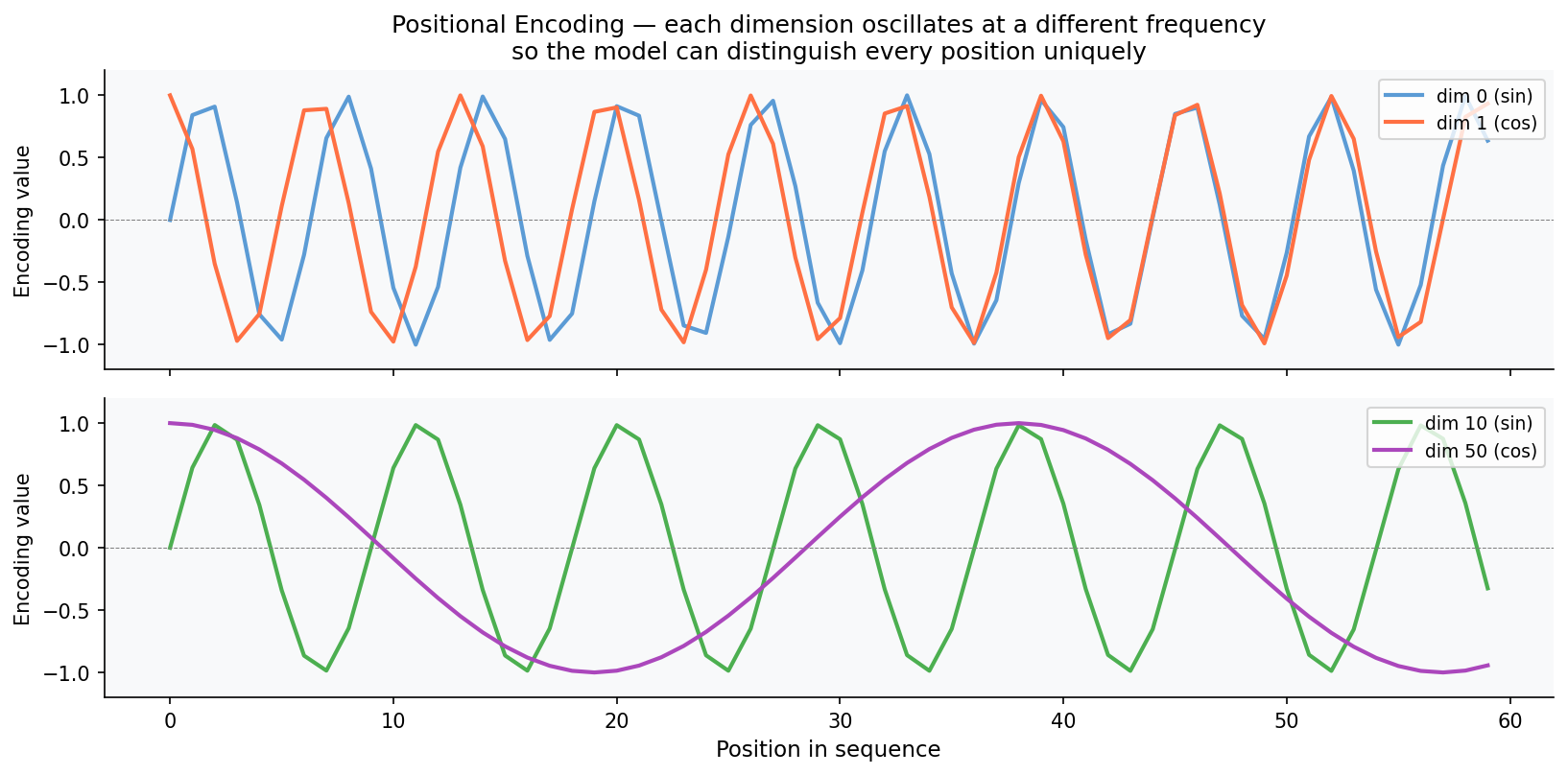
Positional Encoding: Giving the Model a Sense of Order
Here’s a problem: Transformers process all tokens simultaneously. Unlike an RNN that reads left to right and naturally builds up a sense of sequence, the Transformer sees the whole input at once. That means “the dog bit the man” and “the man bit the dog” look identical without some way to encode position.
The solution is positional encoding — a set of signals added to the word embeddings before they enter the encoder.
The formulas from the paper:
PE(pos, 2i) = sin(pos / 10000^(2i / d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i / d_model))
Where pos is the token’s position in the sequence and i indexes the dimension. Here’s a clean implementation:
import numpy as np
def positional_encoding(max_len, d_model):
PE = np.zeros((max_len, d_model))
positions = np.arange(max_len)[:, np.newaxis] # (max_len, 1)
dims = np.arange(0, d_model, 2)[np.newaxis, :] # (1, d_model/2)
angles = positions / np.power(10000, dims / d_model)
PE[:, 0::2] = np.sin(angles) # even indices
PE[:, 1::2] = np.cos(angles) # odd indices
return PE # shape: (max_len, d_model)
Why sine and cosine specifically? The key insight is that any relative offset can be expressed as a linear transformation of the encoding. If you want to shift from position pos to position pos + k, there’s a fixed linear function that does it regardless of what pos is. That means the model can learn to reason about relative distances — “the verb is 3 positions after the subject” — rather than just absolute positions.
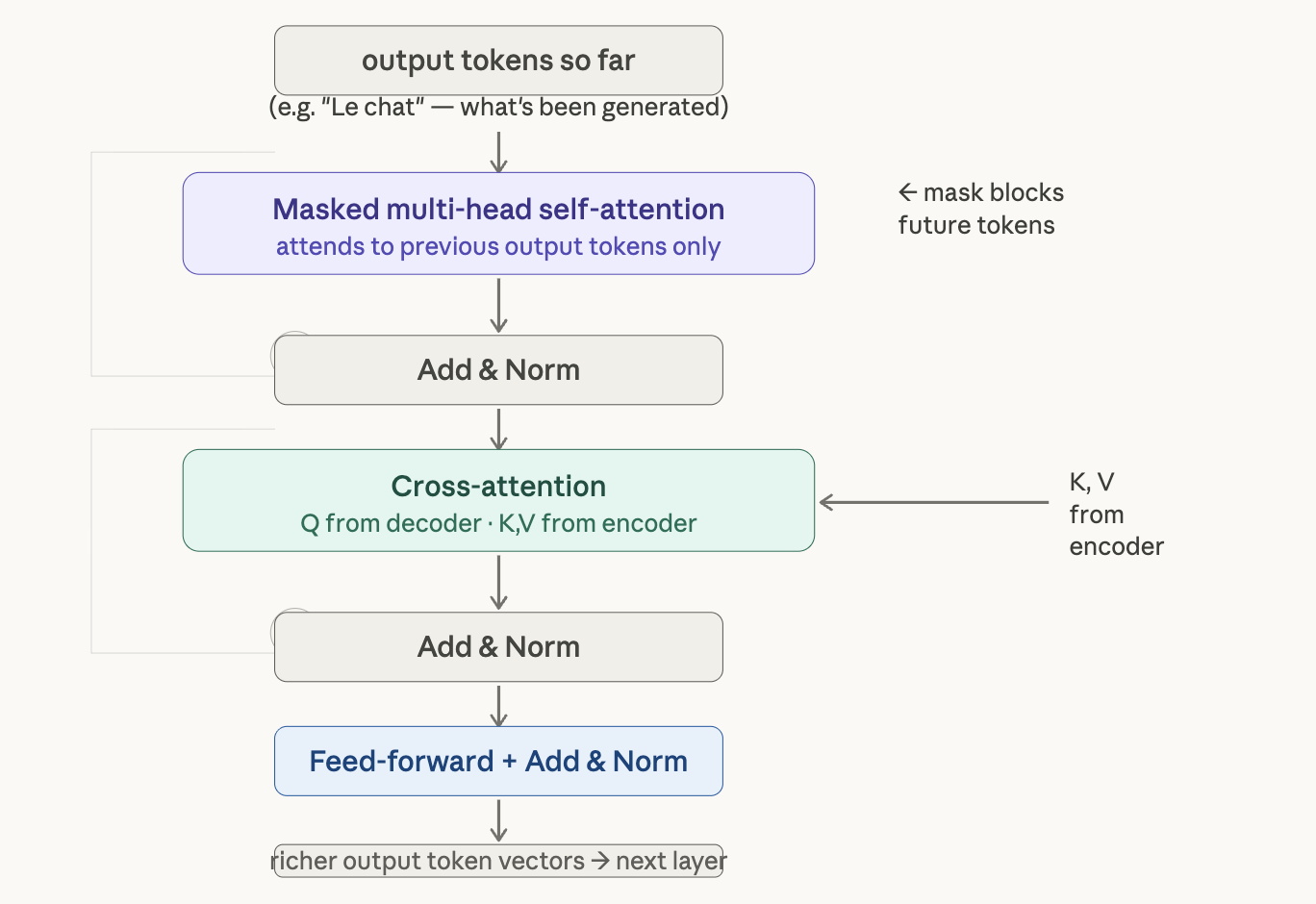
The Decoder Stack
The decoder is also 6 layers, but each layer has three sub-layers instead of two:
- Masked multi-head self-attention
- Cross-attention (encoder-decoder attention)
- Position-wise FFN
Same residual + LayerNorm wrapping applies to all three. The decoder is auto-regressive: it generates one token at a time, and each output token gets fed back in as input for the next step.
Input: "The dog" → Decoder predicts "sat"
Input: "The dog sat" → Decoder predicts "on"
Input: "The dog sat on" → Decoder predicts "the"
This is fundamentally different from the encoder, which processes the full input in one parallel pass.
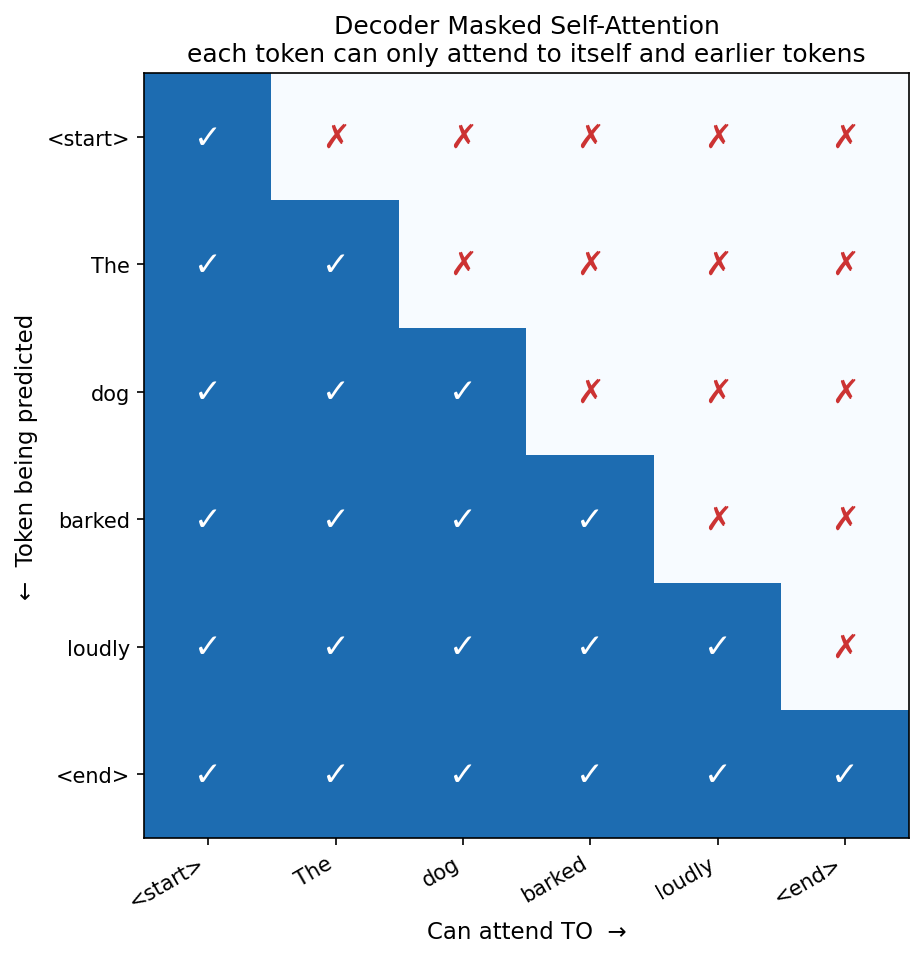
Masked Self-Attention: No Cheating
During training, we have the full target sequence available. It would be computationally wasteful to run the decoder one token at a time when we already know what the output should be. So instead, we feed the entire target sequence in at once — but we apply a mask to prevent each position from attending to future positions.
The mask looks like this for a sequence of length 4:
t=0 t=1 t=2 t=3
t=0 [ 1 0 0 0 ]
t=1 [ 1 1 0 0 ]
t=2 [ 1 1 1 0 ]
t=3 [ 1 1 1 1 ]
In practice, you set the masked positions to -inf before the softmax, so they become zero in the attention weights:
def create_causal_mask(seq_len):
# Upper triangular matrix of ones, then invert
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
return mask # True = positions to mask out
def masked_attention_scores(scores, mask):
scores = scores.masked_fill(mask, float('-inf'))
return torch.softmax(scores, dim=-1)
Without this mask, position t=1 could attend to t=3 during training and just copy the correct answer. The model would learn nothing useful and completely fall apart at inference time when there are no future tokens to peek at. The mask enforces the causal property: each prediction can only depend on previously generated tokens.
Cross-Attention: The Bridge Between Encoder and Decoder
The second sub-layer in each decoder layer is where the encoder and decoder actually talk to each other. It works exactly like regular attention, with one key difference in where the queries, keys, and values come from:
- Queries → from the decoder’s current state
- Keys and Values → from the encoder’s final output
class CrossAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.attention = nn.MultiheadAttention(d_model, num_heads, batch_first=True)
def forward(self, decoder_state, encoder_output):
# decoder_state provides queries
# encoder_output provides keys and values
attn_output, _ = self.attention(
query=decoder_state,
key=encoder_output,
value=encoder_output
)
return attn_output
Here’s a concrete example. Say you’re translating “The dog ran fast” into German. While generating the word “Hund” (dog), the decoder’s cross-attention layer fires a query that looks something like “what animal concept am I generating right now?” The encoder has already built a rich representation of every English word. The cross-attention mechanism will score the encoder’s representation of “dog” very highly, and “ran” and “fast” much lower. That focused signal is what steers the decoder toward outputting “Hund” at the right moment.
This is the mechanism that makes translation — and more broadly, any sequence-to-sequence task — work. The decoder doesn’t have to independently reconstruct what the input meant; it can continuously query the encoder’s representations throughout the generation process.
Putting It Together
The full flow looks like this:
Encoder: Tokenize input → add positional encodings → run through 6 encoder layers (self-attention + FFN) in parallel → produce a rich set of context vectors, one per input token.
Decoder: Start with a
<START>token → add positional encodings → run through 6 decoder layers (masked self-attention → cross-attention with encoder output → FFN) → predict the next token → repeat until<END>.
The encoder does its work once, upfront. The decoder runs N times, where N is the length of the output sequence. Every decoder step attends back to the same frozen encoder output.
Conclusion
The encoder/decoder split is elegant precisely because each half does one job well. The encoder is a parallel machine for building deep contextual representations. The decoder is a careful, step-by-step generator that respects causality through masking and stays grounded in the source through cross-attention. Residual connections and layer norm keep the whole stack trainable at depth, and positional encodings give a fundamentally order-agnostic architecture the information it needs to reason about sequence structure. Once you see how these pieces fit together, the rest of the Transformer — and most of what’s been built on top of it — starts to make a lot more sense.